
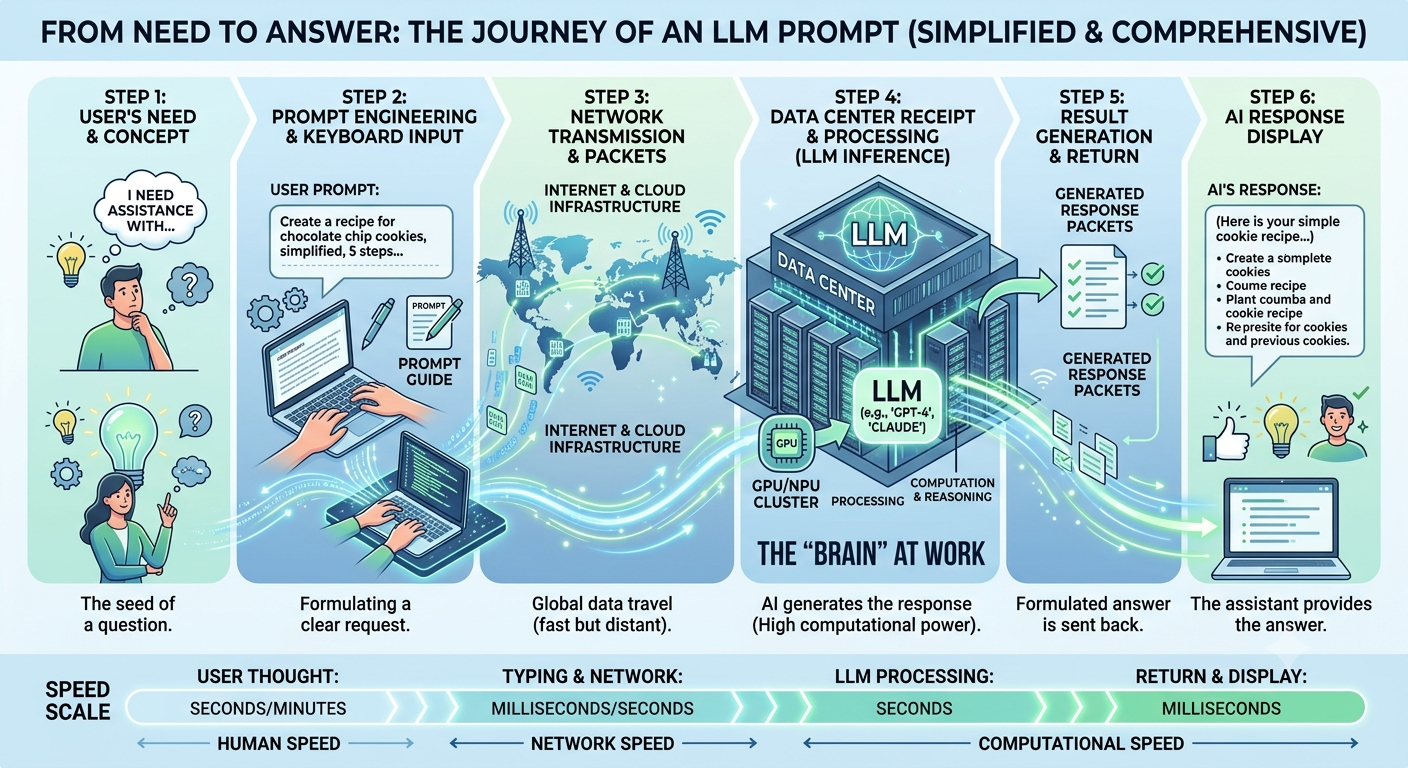
Here is a simplified end-to-end journey of what happens when you ask an AI assistant (such as ChatGPT, Claude, Gemini, DeepSeek, Grok, or similar LLMs) a question. Think of it as a package being delivered from your keyboard to a giant AI factory and then back to your screen.
Step 1. You Think of a Question
Everything starts in your brain.
Example
“How do I build a free-range chicken farm app?”
Location
- Human brain
Time
- Depends on you.
Step 2. You Type the Question
You type using your:
- Keyboard
- Phone screen
- Voice (speech converted into text)
Device
- Laptop
- Desktop
- Smartphone
- Tablet
Speed
About 40–100 words per minute for typing.
Step 3. The App Receives Your Question
The AI application collects your message.
Examples include:
- ChatGPT
- Claude
- Gemini
- Grok
- DeepSeek
- Perplexity
The app checks that your message is complete before sending it.
Typical delay
Less than 10 milliseconds.
Step 4. Internet Connection
Your question leaves your device.
It travels through:
- Wi-Fi or mobile network
- Internet Service Provider (ISP)
- Internet backbone
- Cloud network
Like sending an email, but much faster.
Step 5. The Question Reaches a Data Centre
Your question arrives at a large data centre full of powerful computers.
Typical companies operating AI data centres include:
- OpenAI
- Microsoft
- Amazon Web Services
- Oracle
Inside are:
- Thousands of servers
- Networking equipment
- Massive storage systems
- Cooling systems
- Backup power
Step 6. Security Checks
Before the AI reads your question, the system performs checks such as:
- Authentication
- Security screening
- Spam detection
- Safety checks
- Rate limiting
Typical time:
5–30 milliseconds.
Step 7. Your Words Become Tokens
The AI does not read whole words directly.
It breaks your sentence into smaller pieces called tokens.
Example:
“Build a chicken farm app”
might become:
- Build
- a
- chicken
- farm
- app
or even smaller sub-word pieces depending on the tokenizer.
Large prompts can contain thousands of tokens.
Step 8. Tokens Become Numbers
Computers only understand numbers.
Each token is converted into a numerical ID.
Example:
| Word | Token ID |
|---|---|
| Build | 2815 |
| chicken | 7482 |
| app | 923 |
Now everything is mathematics inside the computer.
Step 9. Numbers Enter the AI Model
The numbers are sent into a Large Language Model (LLM).
Examples include:
- GPT-5.5
- Claude
- Gemini
- Llama
- DeepSeek
- Grok
These models contain billions or even trillions of learned parameters.
Step 10. GPUs Perform Massive Calculations
The AI model runs on powerful AI chips.
Common AI processors include:
- NVIDIA H100
- NVIDIA B200
- NVIDIA Blackwell
- AMD MI300
- Google TPU
These processors perform enormous numbers of mathematical operations every second.
Step 11. The AI Predicts the Next Token
The model predicts one token at a time.
It repeatedly asks:
“What is the most likely next token?”
This happens hundreds or thousands of times until a complete answer is formed.
Step 12. Tokens Become Human Words Again
The predicted tokens are converted back into readable text.
The AI now has a complete answer.
Step 13. The Answer Travels Back
The response travels back through:
- Cloud network
- Internet backbone
- ISP
- Your Wi-Fi or mobile network
Step 14. Your Device Displays the Answer
The app receives the response.
It formats the text and displays it on your screen.
Some apps also display:
- Tables
- Images
- Charts
- Code
- Videos
Step 15. You Read the Answer
The final step is you reading the AI’s response.
If needed, you ask another question, and the process starts again.
Overall Data Flow
Your Brain
│
▼
Keyboard / Voice
│
▼
AI App
│
▼
Internet
│
▼
Cloud Network
│
▼
Data Centre
│
▼
Security Checks
│
▼
Tokenization
│
▼
Numbers (Token IDs)
│
▼
Large Language Model
│
▼
GPU Computation
│
▼
Next-Token Prediction
│
▼
Generated Tokens
│
▼
Readable Text
│
▼
Internet
│
▼
Your Device
│
▼
Your Screen
Typical Speed
| Stage | Approximate Time |
|---|---|
| Keyboard to app | 1–10 ms |
| Internet to data centre | 20–150 ms (depends on location and network) |
| Security checks | 5–30 ms |
| Tokenization | Less than 1 ms |
| AI inference (reasoning and generation begins) | 100 ms to several seconds, depending on model size and prompt |
| Response sent back | 20–150 ms |
| Display on screen | Less than 10 ms |
Typical total response time:
- Simple question: 0.5–2 seconds
- Medium question: 2–10 seconds
- Long or complex question: 10–60+ seconds
Main Components Involved
- Your brain (creates the idea)
- Keyboard or microphone (captures the input)
- AI application (collects the request)
- Internet connection (transports the data)
- Cloud networking (routes the request)
- Data centre (hosts the computing infrastructure)
- Security systems (protect and validate requests)
- Tokenizer (splits text into tokens)
- Embedding and token encoding (converts tokens into numerical representations)
- Large Language Model (processes the request)
- GPUs or AI accelerators (perform the computations)
- Decoder (converts generated tokens back into text)
- Internet (returns the response)
- Your device (renders the answer)
- Your screen (shows the final result)
This is the complete journey—from pressing a key on your keyboard to receiving an AI-generated answer back on your screen.


Be First to Comment