
Abstract
Modern artificial intelligence systems are not monolithic entities but rather complex orchestrations of interconnected layers, each building upon the previous to enable increasingly sophisticated capabilities. This thesis presents a 15-layer framework for understanding AI systems, from foundational physical infrastructure to high-level applications. By examining each layer in isolation and then exploring their interactions through concrete examples, we develop a comprehensive mental model of how AI systems function in the real world.
Introduction: The Stack Metaphor
Understanding modern AI requires thinking in layers, much like understanding a skyscraper requires examining its foundation, structural framework, utilities, and interior spaces. Each layer serves a specific purpose, depends on layers below it, and enables layers above it. When we interact with an AI chatbot or use an AI agent to book a flight, we’re touching only the topmost layer of a deep stack of technologies, each essential to the system’s function.
This framework provides a systematic way to comprehend how electricity flowing through data centers ultimately manifests as intelligent behavior in applications we use daily.
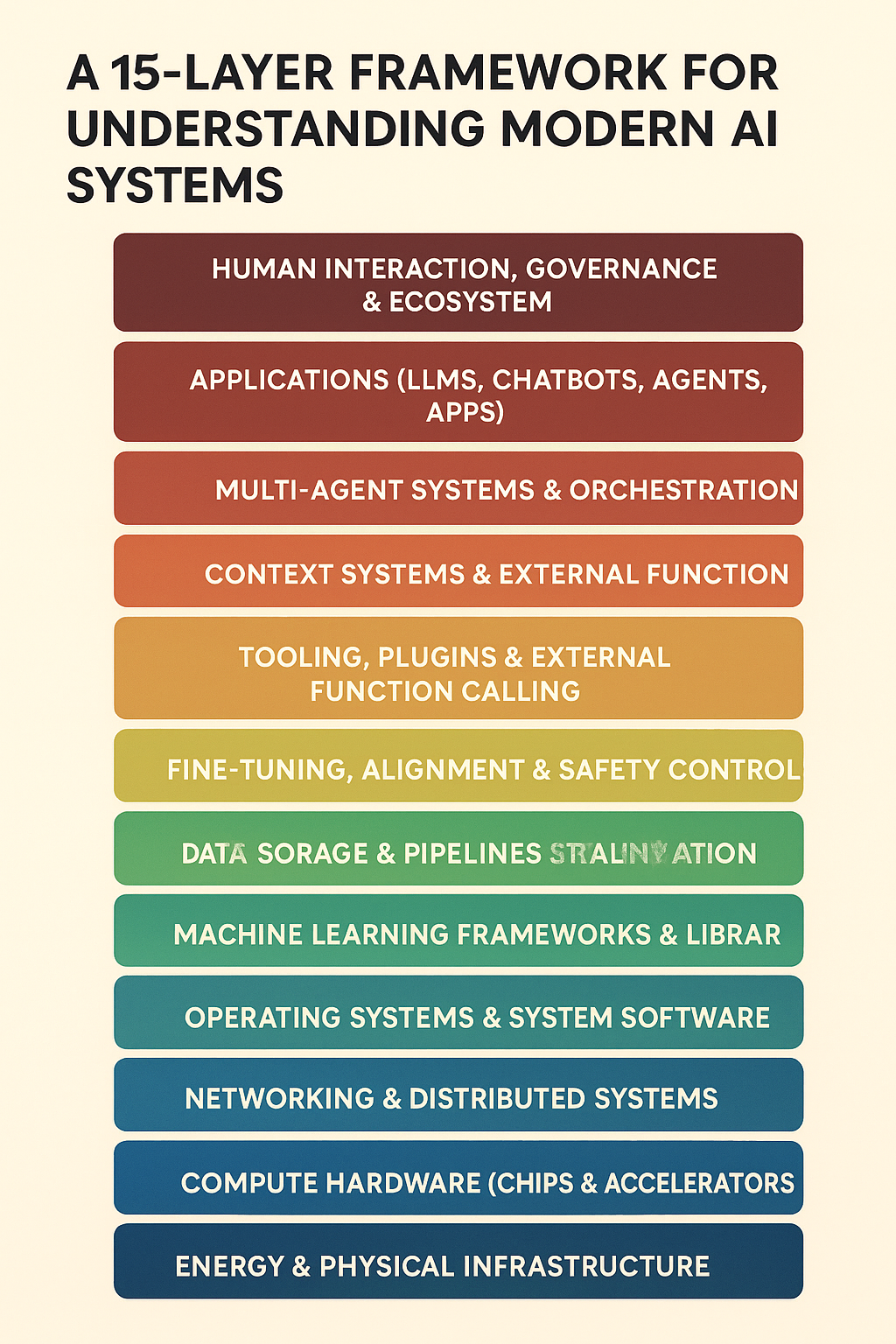
The 15 Layers: From Foundation to Application
Layer 1: Physical Energy Infrastructure
What it is: The electrical power generation and distribution systems that provide energy to computational hardware.
Why it matters: AI computation is extraordinarily energy-intensive. Large language models require megawatts of power during training—equivalent to the consumption of thousands of homes. Without reliable, high-capacity electrical infrastructure, modern AI simply cannot exist.
Key components:
- Power plants (fossil fuel, nuclear, renewable)
- Electrical grids and distribution networks
- Backup power systems and uninterruptible power supplies
- Power management and cooling systems
Real-world considerations: Training GPT-3 consumed approximately 1,287 MWh of electricity. Data centers housing AI infrastructure now account for 1-2% of global electricity consumption, a figure expected to grow dramatically.
Layer 2: Computational Hardware
What it is: The physical processors and computing equipment that perform calculations.
Why it matters: AI computations require specialized hardware optimized for the massive parallel matrix operations that power neural networks.
Key components:
- GPUs (Graphics Processing Units): Originally designed for rendering graphics, now the workhorse of AI training due to their ability to perform thousands of calculations simultaneously
- TPUs (Tensor Processing Units): Google’s custom-designed chips optimized specifically for neural network operations
- CPUs (Central Processing Units): General-purpose processors that coordinate operations
- Specialized AI accelerators: Custom chips from companies like Cerebras, Graphcore, and others
Technical detail: A modern NVIDIA H100 GPU contains 80 billion transistors and can perform 60 trillion floating-point operations per second (TFLOPS) for AI workloads. Training large models often requires thousands of these chips working in concert.
Layer 3: Memory and Storage Systems
What it is: Systems for temporarily holding data during computation (RAM) and permanently storing data (disk storage).
Why it matters: AI models and datasets are enormous. A single large language model might occupy hundreds of gigabytes in memory, while training datasets can span petabytes.
Key components:
- High-bandwidth memory (HBM): Extremely fast memory directly connected to GPUs
- System RAM: Traditional computer memory for CPU operations
- SSD storage: Fast solid-state drives for active datasets
- Distributed storage systems: Networked storage across multiple machines (like Google’s Colossus or Amazon’s S3)
- Archival storage: Tape drives and cold storage for long-term data retention
Scale perspective: Training a large language model might require reading through terabytes of text data multiple times, necessitating storage systems that can deliver data at hundreds of gigabytes per second.
Layer 4: Networking Infrastructure
What it is: The communication systems that connect computers to each other and to the internet.
Why it matters: Modern AI training distributes computation across thousands of machines. These machines must communicate constantly to coordinate their work. Additionally, AI applications must deliver results to users across the globe.
Key components:
- Datacenter interconnects: Ultra-high-speed networks (400 Gbps and beyond) connecting machines within AI clusters
- InfiniBand and RoCE: Low-latency networking protocols for distributed training
- Content delivery networks (CDNs): Systems for delivering AI application responses to users quickly
- Internet backbone infrastructure: The global network enabling AI services
Technical insight: During distributed training, GPUs must synchronize their gradients multiple times per second. Even milliseconds of network latency can create bottlenecks that slow training dramatically.
Layer 5: Operating Systems and Virtualization
What it is: Software that manages hardware resources and provides an environment for applications to run.
Why it matters: Operating systems abstract the complexity of hardware, allowing AI software to run consistently across different machines. Virtualization enables efficient resource sharing across many users and applications.
Key components:
- Linux distributions: The dominant OS for AI workloads (Ubuntu, CentOS, etc.)
- Container systems: Docker and similar technologies for packaging AI applications
- Orchestration platforms: Kubernetes for managing large-scale distributed systems
- Hypervisors: VMware, KVM, and others for hardware virtualization
Practical application: An AI researcher can develop a model on their laptop, package it in a Docker container, and deploy it to cloud infrastructure where it runs identically, regardless of the underlying hardware differences.
Layer 6: Programming Languages and Runtimes
What it is: The languages developers use to write AI software and the systems that execute that code.
Why it matters: Programming languages provide the vocabulary for expressing AI algorithms. The choice of language affects development speed, performance, and ecosystem access.
Key components:
- Python: The dominant language for AI development, valued for readability and extensive libraries
- C++/CUDA: Used for performance-critical code and GPU programming
- Julia: Emerging language combining Python’s ease with C++’s speed
- JavaScript/TypeScript: For AI applications in web browsers
- Specialized languages: Languages like JAX for automatic differentiation
Why Python dominates: Python’s simple syntax, dynamic typing, and massive ecosystem of libraries make it ideal for rapid experimentation—essential in AI research where ideas evolve quickly.
Layer 7: Mathematical and Computing Libraries
What it is: Pre-built software libraries that implement fundamental mathematical operations and computing primitives.
Why it matters: These libraries provide optimized, reliable implementations of the mathematical operations that form the building blocks of AI.
Key components:
- BLAS (Basic Linear Algebra Subprograms): Fundamental vector and matrix operations
- cuBLAS/cuDNN: NVIDIA’s GPU-accelerated mathematical libraries
- MKL (Math Kernel Library): Intel’s optimized mathematical functions
- NumPy: Python’s foundational array computing library
- Apache Arrow: High-performance data interchange format
Hidden optimization: When you multiply two matrices in PyTorch, the actual computation happens in highly optimized C++/CUDA code that’s been fine-tuned by hardware vendors to extract maximum performance from specific chips.
Layer 8: Machine Learning Frameworks
What it is: High-level software frameworks that provide tools for building, training, and deploying AI models.
Why it matters: These frameworks abstract away low-level details like gradient computation and GPU memory management, allowing developers to focus on model architecture and experimentation.
Key components:
- PyTorch: Facebook/Meta’s framework, dominant in research for its flexibility
- TensorFlow: Google’s framework, popular for production deployments
- JAX: Google’s research framework emphasizing functional programming
- Keras: High-level API (now integrated into TensorFlow)
- Scikit-learn: Library for traditional machine learning algorithms
Framework capabilities:
- Automatic differentiation (computing gradients automatically)
- Distributed training across multiple GPUs/machines
- Model serialization and loading
- Pre-built model architectures
- Integration with deployment systems
Example code concept: In PyTorch, you can define a neural network in just a few lines, and the framework handles all the complex mathematics of backpropagation automatically.
Layer 9: Training Data and Data Processing
What it is: The raw information used to teach AI models and the systems for collecting, cleaning, and preparing it.
Why it matters: “Garbage in, garbage out” applies emphatically to AI. The quality, diversity, and scale of training data fundamentally determine what models can learn.
Key components:
- Data sources: Web scraping, licensed datasets, proprietary data, synthetic data
- Data formats: Text corpora, image datasets, audio files, structured databases
- Data processing pipelines: Systems for cleaning, filtering, and transforming raw data
- Data labeling: Human annotation for supervised learning tasks
- Data augmentation: Techniques for artificially expanding datasets
Real-world datasets:
- Common Crawl: Petabytes of web data used to train language models
- ImageNet: 14 million labeled images for computer vision
- The Pile: 825 GB of diverse text for language model training
- YouTube-8M: Millions of labeled videos
Data quality challenges: Modern LLMs are trained on trillions of words, but this data contains biases, errors, and toxic content. Extensive filtering and curation is necessary but imperfect.
Layer 10: Model Architectures
What it is: The mathematical structures and designs that define how AI models process information.
Why it matters: Architecture determines what patterns a model can learn, how efficiently it trains, and what tasks it can perform.
Key architectural patterns:
Transformers (2017-present):
- Core innovation: Self-attention mechanism that allows models to weigh the importance of different parts of the input
- Structure: Encoder-decoder or decoder-only arrangements of attention and feedforward layers
- Applications: Language models (GPT, Claude), vision models, multimodal systems
- Key advantage: Parallelizable training, effective long-range dependencies
Convolutional Neural Networks (CNNs):
- Core innovation: Convolutional filters that detect spatial patterns
- Structure: Stacked convolutional layers with pooling and normalization
- Applications: Image classification, object detection, medical imaging
- Key advantage: Translation invariance, parameter efficiency for spatial data
Recurrent Neural Networks (RNNs/LSTMs):
- Core innovation: Internal state that evolves over sequence steps
- Structure: Loops that pass information from one step to the next
- Applications: Time series, speech recognition (now largely replaced by Transformers)
- Key limitation: Sequential processing limits training parallelization
Architectural components:
- Attention mechanisms: Computing relevance scores between elements
- Normalization layers: Stabilizing training (LayerNorm, BatchNorm)
- Activation functions: Non-linear transformations (ReLU, GELU, SiLU)
- Positional encodings: Providing sequence order information
- Residual connections: Allowing gradients to flow through deep networks
Layer 11: Training Algorithms and Optimization
What it is: The mathematical procedures for adjusting model parameters to improve performance.
Why it matters: Training is the process by which random model parameters evolve into useful representations. The choice of training algorithm affects convergence speed, final performance, and resource requirements.
Core concepts:
Gradient Descent: The fundamental algorithm: adjust parameters in the direction that reduces error. Modern variants include:
- SGD (Stochastic Gradient Descent): Update parameters using small batches of data
- Adam: Adaptive learning rates for each parameter
- AdamW: Adam with improved weight decay
- Lion: Recent optimizer using sign operations
Loss Functions: Objectives that quantify model error:
- Cross-entropy loss: For classification tasks
- Mean squared error: For regression
- Contrastive losses: For learning representations
- Reinforcement learning objectives: For agent training
Training Techniques:
- Learning rate scheduling: Gradually reducing step sizes during training
- Gradient clipping: Preventing explosive gradients
- Mixed-precision training: Using 16-bit floats to speed training
- Gradient accumulation: Simulating larger batches on limited hardware
- Distributed training strategies: Data parallelism, model parallelism, pipeline parallelism
Modern refinements:
- Reinforcement Learning from Human Feedback (RLHF): Using human preferences to align models
- Constitutional AI: Training models to follow principles
- Curriculum learning: Ordering training examples from simple to complex
Layer 12: Trained Models and Model Weights
What it is: The final product of training—billions of numerical parameters that encode learned patterns and capabilities.
Why it matters: These weights are the “knowledge” of the AI system. They determine everything the model can and cannot do.
Model characteristics:
Scale:
- Small models: Millions to billions of parameters (good for mobile/edge deployment)
- Large models: 10s to 100s of billions of parameters (state-of-the-art capabilities)
- Massive models: Trillions of parameters (cutting-edge research, mixture-of-experts)
Format:
- Stored as large binary files (often gigabytes to hundreds of gigabytes)
- Organized as tensors (multi-dimensional arrays)
- Often compressed using quantization (reducing precision to save space)
Model families:
- Base models: Trained only on next-token prediction
- Instruction-tuned models: Fine-tuned to follow instructions
- Chat models: Further refined for conversational interaction
- Specialized models: Adapted for specific domains (medical, legal, code)
Distribution and access:
- Proprietary models: Weights kept secret, accessed only via API (GPT-4, Claude)
- Open-weight models: Weights publicly released (Llama, Mistral)
- Checkpoint sharing: Platforms like Hugging Face hosting thousands of models
Layer 13: Inference Infrastructure
What it is: The systems and techniques for using trained models to make predictions on new inputs.
Why it matters: Training happens once; inference happens billions of times. Efficient inference determines the cost, speed, and accessibility of AI applications.
Inference optimizations:
Model optimization:
- Quantization: Reducing parameter precision (32-bit → 8-bit or 4-bit) for faster computation
- Pruning: Removing unnecessary connections in the network
- Distillation: Training smaller models to mimic larger ones
- Compilation: Optimizing model code for specific hardware
Serving infrastructure:
- Batch processing: Grouping multiple requests together for efficiency
- Request routing: Directing queries to appropriate instances
- Load balancing: Distributing work across multiple servers
- Caching: Storing common responses to avoid recomputation
- Edge deployment: Running models on user devices rather than servers
Specialized inference hardware:
- Inference-optimized GPUs: Cards designed for deployment rather than training
- AI accelerators: Custom chips like Google’s Edge TPU or Apple’s Neural Engine
- FPGAs: Programmable chips offering flexibility and efficiency
Performance metrics:
- Latency: Time from request to response (critical for user experience)
- Throughput: Requests processed per second (critical for scale)
- Cost per query: Economic efficiency of serving predictions
Layer 14: Application Programming Interfaces (APIs) and Tools
What it is: The interfaces that allow developers to integrate AI capabilities into applications without managing infrastructure.
Why it matters: APIs democratize access to AI, allowing developers to build sophisticated applications without expertise in training models or managing infrastructure.
API types:
Model APIs:
- Text generation: OpenAI, Anthropic, Google APIs for language models
- Image generation: DALL-E, Midjourney, Stable Diffusion APIs
- Speech: Whisper for transcription, text-to-speech services
- Embedding: Converting text/images to vector representations
Orchestration frameworks:
- LangChain: Framework for building LLM applications with chains and agents
- LlamaIndex: Tools for connecting LLMs to external data sources
- Semantic Kernel: Microsoft’s framework for AI orchestration
- AutoGPT/BabyAGI: Frameworks for autonomous agent loops
Developer tools:
- Prompt engineering libraries: Tools for constructing effective prompts
- Vector databases: Pinecone, Weaviate, Chroma for semantic search
- Observability platforms: Monitoring and debugging LLM applications
- Evaluation frameworks: Testing model outputs systematically
Integration patterns:
- Direct API calls: Simple request-response interaction
- Streaming: Real-time token-by-token response delivery
- Function calling: Allowing models to invoke tools and APIs
- Retrieval-Augmented Generation (RAG): Combining models with external knowledge
Layer 15: End-User Applications
What it is: The software products and experiences that users directly interact with, powered by all layers beneath.
Why it matters: This is where AI value is realized—solving real problems and enhancing human capabilities.
Application categories:
Conversational AI:
- Chatbots: Customer service, general assistance (ChatGPT, Claude, Gemini)
- Coding assistants: GitHub Copilot, Cursor, Replit AI
- Writing assistants: Grammarly, Jasper, Copy.ai
- Search engines: Perplexity, You.com, AI-enhanced Google/Bing
Creative tools:
- Image generation: Midjourney, DALL-E, Stable Diffusion interfaces
- Video generation: Runway, Pika, emerging video models
- Music generation: Suno, Udio, AIVA
- Design assistance: Adobe Firefly, Canva AI features
Productivity applications:
- Note-taking: Notion AI, Obsidian with AI plugins
- Meeting assistants: Otter.ai, Fireflies, Microsoft Copilot
- Email management: Gmail Smart Compose, Superhuman AI
- Document analysis: ChatPDF, Humata, AI document processors
Specialized applications:
- Healthcare: Diagnostic assistance, drug discovery, medical imaging
- Education: Personalized tutoring, curriculum generation, assessment
- Legal: Contract analysis, legal research, document drafting
- Finance: Risk assessment, fraud detection, algorithmic trading
Autonomous agents:
- Task automation: Zapier AI, Make.com with AI
- Research agents: Systems that browse web and synthesize information
- Multi-step workflows: Agents that plan and execute complex tasks
- Robotic control: AI systems controlling physical robots
Deep Dive: How an LLM Uses All 15 Layers
Let’s trace how a specific LLM—we’ll call it “Rowan”—utilizes every layer of the framework when a user asks it a question. This concrete example illuminates the deep integration across the stack.
The User Query: “Explain quantum entanglement in simple terms”
Phase 1: The Request Arrives (Layers 15 → 14)
Layer 15 (Application): The user types their question into a chat interface—perhaps a web application with a clean text box and conversation history. They press enter.
Layer 14 (API): The application sends an HTTP POST request to Rowan’s API endpoint:
POST https://api.rowan.ai/v1/chat/completions
{
"model": "rowan-large-v2",
"messages": [{"role": "user", "content": "Explain quantum entanglement in simple terms"}],
"temperature": 0.7,
"max_tokens": 500
}Phase 2: Infrastructure Routing (Layers 13 → 4)
Layer 13 (Inference Infrastructure): Rowan’s load balancer receives the request. It examines current server load and routes the request to an available inference server in a data center in Virginia. This server has a GPU with Rowan’s model weights already loaded in memory.
Layer 4 (Networking): The request travels through the internet backbone, through the data center’s network switches, and arrives at the designated server. Total time: ~50 milliseconds.
Phase 3: Preparing for Computation (Layers 5 → 6)
Layer 5 (Operating System): The Linux kernel on the inference server receives the network packet. The containerized application (running in Docker, orchestrated by Kubernetes) handles the request.
Layer 6 (Programming Language): A Python process receives the API request. The FastAPI web framework parses the JSON and passes it to Rowan’s inference code.
Phase 4: Text to Numbers (Layers 12 → 9)
Layer 12 (Model Weights) + Layer 9 (Data Processing): Rowan must convert the text into numbers. The input string is tokenized using a trained vocabulary of ~50,000 tokens:
"Explain" → token ID 8734
"quantum" → token ID 23891
"entanglement" → token ID 41203
"in" → token ID 287
"simple" → token ID 4758
"terms" → token ID 5621The tokenizer also adds special tokens indicating this is a user message in a chat format.
Phase 5: The Forward Pass Begins (Layers 10 → 8 → 7 → 2)
Layer 10 (Model Architecture): Rowan is a Transformer-based model with 40 billion parameters, organized into 60 layers. Each layer has multi-head attention and feedforward components.
Layer 8 (ML Framework): PyTorch manages the computation. It sends instructions to the GPU.
Layer 7 (Math Libraries): cuBLAS and cuDNN libraries execute the actual mathematical operations.
Layer 2 (Hardware): The GPU’s 16,896 CUDA cores spring into action.
The computation:
- Token Embedding: Each token ID is converted to a 8192-dimensional vector by looking up the embedding matrix (stored in Layer 12’s weights). Our 6 tokens become a 6×8192 matrix.
- Positional Encoding: Position information is added to each token embedding, so Rowan knows “quantum” comes before “entanglement.”
- Layer 1 – Attention:
- The attention mechanism computes relationships between all token pairs
- “entanglement” strongly attends to “quantum” (they’re semantically related)
- “simple” and “terms” attend to “Explain” (they modify the request type)
- This requires matrix multiplications: 6×8192 matrices multiplied multiple times
- The GPU computes these operations in parallel across 32 attention heads
- Layer 1 – Feedforward:
- Each token’s representation passes through a feedforward network
- Matrix multiplication: 8192×32768 → 32768×8192
- Billions of multiply-accumulate operations happening simultaneously on the GPU
- Layers 2-60: The computation repeats through 59 more layers, each refining the representations further.
Layer 3 (Memory): As computation proceeds:
- The model weights (80 GB) reside in GPU high-bandwidth memory
- Intermediate activations (the evolving token representations) are stored temporarily
- The GPU’s memory controller orchestrates data movement at 3 TB/s
Layer 1 (Electricity): During these ~200 milliseconds of computation, the GPU draws 700 watts of power—like running seven incandescent light bulbs.
Phase 6: Generating the Response (Layers 12 → 10)
Layer 10 (Architecture) + Layer 12 (Weights): After 60 layers, Rowan has a representation for each input token. Now it must generate output tokens.
Token 1 – “Quantum”:
- The final layer outputs a probability distribution over all 50,000 possible next tokens
- Layer 7 (cuBLAS) computes: final_representation × output_matrix (8192 × 50,000 matrix)
- Softmax normalizes to probabilities
- “Quantum” has probability 0.23, “Entanglement” 0.19, “In” 0.08…
- Sampling (with temperature=0.7) selects “Quantum”
Token 2 – “entanglement”:
- “Quantum” is appended to the input sequence
- Another forward pass through all 60 layers
- Now “entanglement” is predicted with high probability
- This continues token by token…
Tokens 3-150: Over the next 2 seconds, Rowan generates approximately 150 tokens:
“Quantum entanglement is a phenomenon where two particles become connected in such a way that the state of one instantly influences the other, no matter how far apart they are. Think of it like having two magic coins: when you flip one and it lands on heads, the other automatically becomes tails—even if it’s on the other side of the universe. This ‘spooky action at a distance,’ as Einstein called it, doesn’t let you send information faster than light, but it does mean the particles share a deep connection that defies our everyday intuition about how separate objects should behave.”
Phase 7: Streaming the Response (Layers 13 → 14 → 15)
Layer 13 (Inference): Rather than waiting for all 150 tokens, Rowan streams them as they’re generated:
Layer 14 (API): Every few tokens, a chunk is sent via HTTP streaming:
data: {"choices":[{"delta":{"content":"Quantum entanglement"}}]}
data: {"choices":[{"delta":{"content":" is a phenomenon"}}]}
...Layer 4 (Networking): Each chunk travels back through data center networks, across the internet, to the user’s device.
Layer 15 (Application): The user’s browser receives chunks and displays them in real-time, creating the characteristic “typing” effect of modern AI chatbots.
Phase 8: Completion and Cleanup (All Layers)
Final metrics:
- Total latency: ~2.5 seconds
- Tokens generated: 150
- Energy consumed: ~1.75 watt-hours (Layer 1)
- GPU utilization: 85% (Layer 2)
- Memory peak: 83 GB (Layer 3)
- Cost: ~$0.003 at typical API pricing
Layer 13 (Inference): The server logs metrics, releases GPU memory for the next request, and stands ready.
Layer 5 (OS): System resources are freed. The container remains running, model weights stay in memory for subsequent requests.
Deep Dive: How an AI Agent Uses All 15 Layers
Now let’s examine a more complex scenario: an AI agent booking a flight. This demonstrates how applications (Layer 15) orchestrate multiple calls through the entire stack to accomplish multi-step tasks.
The Agent: “FlightBooker”
User request: “Book me a round-trip flight from New York to London, departing December 15, returning December 22, under $800, prefer morning flights.”
Phase 1: Request Decomposition (Layers 15 → 14 → 12)
Layer 15 (Application): FlightBooker is built using LangChain, an orchestration framework. It receives the user’s natural language request.
Layer 14 (APIs): The agent makes its first LLM call to an underlying model (like Rowan) through API:
Request 1: "Analyze this user request and extract structured information: [user request]"Layers 12 → 2 (Full stack): The LLM processes this meta-request through all layers (as detailed in the previous example).
Response from LLM:
json
{
"task": "flight_booking",
"departure_city": "New York",
"arrival_city": "London",
"departure_date": "2025-12-15",
"return_date": "2025-12-22",
"max_price": 800,
"preferences": ["morning_flights"],
"trip_type": "round_trip"
}Phase 2: Tool Planning (Layer 15 → 14)
Layer 15 (Agent Logic): FlightBooker has access to several tools:
search_flights(from, to, date)– queries flight APIget_user_preferences()– retrieves user profilecalculate_dates(description)– converts relative datesbook_flight(flight_id)– makes actual booking
Layer 14 (API): Second LLM call for planning:
Request 2: "Given these tools [tool descriptions] and this goal [extracted info],
create a step-by-step plan to accomplish the task."LLM Response (through full stack):
Plan:
1. Search outbound flights: NYC → London on Dec 15
2. Search return flights: London → NYC on Dec 22
3. Filter results for morning departures and price < $800
4. Present options to user
5. Upon user selection, execute bookingPhase 3: Tool Execution Loop (Multiple Stack Traversals)
Step 1: Search Outbound Flights
Layer 15 (Agent): Executes tool call: search_flights("NYC", "LON", "2025-12-15")
Layer 4 (Networking): HTTP request to flight aggregator API (e.g., Skyscanner):
GET https://api.flightprovider.com/search?from=JFK&to=LHR&date=2025-12-15External System: The flight API queries airline databases and returns JSON with 47 flight options.
Layer 15 (Agent): Receives flight data, stores in working memory.
Step 2: Search Return Flights
Repeats the process for return flights. Receives 52 options.
Step 3: Filtering and Analysis
Layer 14 (API): Third LLM call:
Request 3: "Given these 99 flight options [data], filter for:
- Morning departures (before 11 AM)
- Round-trip combinations under $800
- Rank by best value considering time and price"Full Stack Processing:
Layer 9 (Data): The LLM’s context window now contains ~8,000 tokens of flight data.
Layer 10 (Architecture): The attention mechanism processes relationships:
- Connects outbound and return flights from same airline
- Attends to departure times and relates them to “morning” preference
- Computes price sums for combinations
Layer 2 (Hardware): This is a larger computation—processing 8,000 tokens through 60 layers requires ~500 milliseconds of GPU time.
Layer 1 (Electricity): Another ~350 milliwatt-hours consumed.
LLM Response:
Top 3 combinations meeting criteria:
1. British Airways: JFK→LHR 8:45 AM, LHR→JFK 9:15 AM ($765)
2. Virgin Atlantic: JFK→LHR 10:30 AM, LHR→JFK 9:00 AM ($742)
3. American: JFK→LHR 9:00 AM, LHR→JFK 8:30 AM ($788)Phase 4: User Interaction and Confirmation
Layer 15 (Application UI): The agent presents options to the user through a web interface:
“I found 3 morning flight options within your budget. The best value is Virgin Atlantic at $742 total. Would you like me to proceed with booking?”
User: “Yes, book option 2.”
Phase 5: Final Execution
Layer 15 (Agent): Executes book_flight(virgin_atlantic_combo_id)
Layer 4 (Networking): Multiple API calls:
- Call to payment processor (Stripe API) to authorize $742
- Call to Virgin Atlantic API to reserve seats
- Call to email service (SendGrid) to send confirmation
Each external API call involves:
- Layer 5 (OS): Process management for network requests
- Layer 4 (Networking): HTTPS encrypted communication
- Multiple layers in external systems: Each external service has its own full stack
Phase 6: Summary Generation
Layer 14 (API): Final LLM call:
Request 4: "Generate a friendly confirmation message with these booking details: [details]"Through full stack: Generates personalized message.
Layer 15 (Application): Displays:
“Great! I’ve booked your round-trip flights on Virgin Atlantic. You’ll depart JFK at 10:30 AM on December 15, arriving at Heathrow at 10:45 PM local time. Your return is December 22 at 9:00 AM from Heathrow, landing at JFK at 11:30 AM. Total cost: $742. Confirmation email sent to your address. Have a wonderful trip!”
Complete Resource Utilization for the Agent Task
Let’s trace what this multi-step agent workflow required from each layer:
Layer 1 (Electricity): ~2 watt-hours total across all LLM calls
Layer 2 (Hardware):
- 4 GPU inference passes (each ~200-500ms)
- CPU processing for API orchestration
- Total compute: ~1.5 seconds of GPU time
Layer 3 (Memory):
- Model weights: 80 GB (persistent in GPU memory)
- Context for each call: 2-8K tokens
- Agent state: ~1 MB for conversation history and intermediate results


Be First to Comment